

AI is about making machines think and act like human beings. Human beings go through a learning process to know and be able to do certain things. So there should be a way in which machine are also "taught" how to perform certain tasks that are done by humans. However, training a machine is not the same as training a human.
From the dictionary, to train, means teach (a person or animal) a particular skill or type of behavior through practice and instruction over a period of time. As mentioned by Federico, there are three components to this:
The outcome of any successful training is independence of the person being trained. It means at some point the person being trained will be capable of performing the task without reliance to the input from the trainer.
When training a machine, it is split into two parts:
Supervised Learning
Supervised Learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. So, in Supervised Learning, we have a set of data in which we know the input and the output (we also say: data is labeled) and we train the ML model in predicting the output of unseen data.
The overall process of training a machine learning model using supervised learning technique is as follows:
Un-Supervised Learning
Here the data is not labeled. Meaning we do not know the output of the function from input data. Unsupervised learning uses machine learning algorithms to analyze and cluster (meaning “grouping”) unlabeled data sets. These algorithms discover hidden patterns in data without the need for human intervention, and this is why the case is “unsupervised”.
So, Unsupervised Learning models work on their own to discover the “innate” structure of unlabeled data. This means a simple thing: there is no training on the Unsupervised Learning case. In this case, the algorithm works on its own on finding how to group the (unlabeled) data, so the human doesn't train the model.
Empirical Risk Minimization
Training a model simply means learning (determining) good values for all the weights and the bias from labeled examples. In supervised learning, a machine learning algorithm builds a model by examining many examples and attempting to find a model that minimizes loss; this process is called empirical risk minimization.
Loss is the penalty for a bad prediction. That is, loss is a number indicating how bad the model's prediction was on a single example. If the model's prediction is perfect, the loss is zero; otherwise, the loss is greater. The goal of training a model is to find a set of weights and biases that have low loss, on average, across all examples.
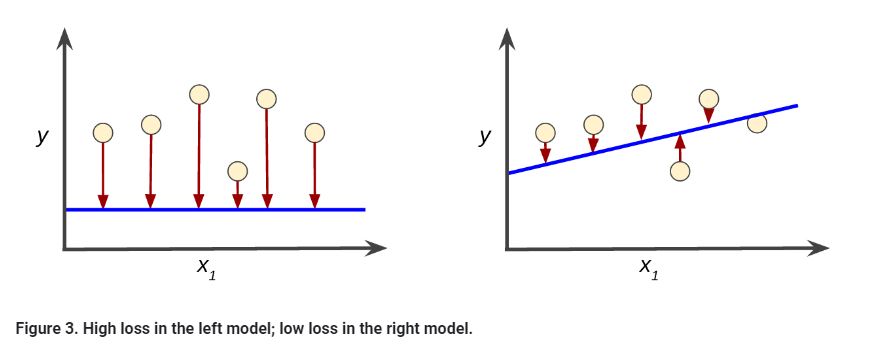
Objective Function / Loss Function
When training you need to select a specific loss function that you will use to minimize or maximize the loss. These loss function are categorized into either regression or classification loss functions.
Please follow the below links to access the loss functions for either:
Sources


