When training a machine learning model, especially when working with huge dataset, it is important to create a sample representative of the the entire dataset in order to avoid out of memory problem when loading the dataset for training purposes.
In order to solve the problem of "out of memory" when working with large datasets, you need to have a way of picking a subset of the data in a manner that the subset data ends up being a good representation of the entire dataset in terms of both content and seasonality.
Sampling
This is a technique that allows us to get information about the population based on the statistics from a subset of the population (sample), without having to investigate every individual.
Sampling Framework (Steps)
- Identify and define the target population
- Select the sampling frame - this is a list of items or people forming a population from which the sample is taken.
- Choose a sampling method - Generally, probability sampling methods are used because every vote has equal value and any person can be included in the sample irrespective of his caste, community, or religion. Different samples are taken from different regions all over the country.
- Sample Size - It is the number of individuals or items to be taken in a sample that would be enough to make inferences about the population with the desired level of accuracy and precision. The larger the sample size, the more accurate our inference about the population would be.
- Collect the required data
Probability Sampling
Probability sampling gives us the best chance to create a sample that is truly representative of the population.
Types of Probability Sampling Techniques
- Simple random sampling - Here, every individual is chosen entirely by chance and each member of the population has an equal chance of being selected, thus their probabilities form a uniform distribution. For example, if you want to sample 5 out of a 10 population, the probability of every element being selected is 0.5. Simple random sampling reduces selection bias. Simple random sampling reduces the chances of sampling error. Sampling error is lowest in this method out of all the methods.
- The method is straightforward and easy to implement, but the rare classes in the population might not be sampled in the selection. Suppose you want to sample 1% from your data, but a rare class appears only in 0.01% of the population: samples of this rare class might not be selected. In this condition, models trained with the sampled subsets might not know the existence of the rare class.
- Stratified random sampling - To avoid the drawbacks of simple random sampling, you can divide the population to several groups according to your requirements, for example the labels, and sample from each group separately. Each group is called a stratum and this method is called stratified sampling. We then select the sample(s) from these stratum. We use this type of sampling when we want representation from all the subgroups of the population. However, stratified sampling requires proper knowledge of the characteristics of the population.
- For example, to sample 1% of a population that has classes A and B, you can divide the population to two groups and sample 1% from the two groups, respectively. In this way, no matter how rare A or B is, the sampled subsets are ensured to contain both of the two classes.
- However, a drawback of stratified sampling is that the population is not always dividable. For example, in a multi-label learning task in which each sample has multiple labels, it is challenging to divide the population according to different labels.
- Weighted Sampling - In weighted sampling, each sample is assigned a weight—the probability of being sampled. For example, for a population containing classes A and B, if you assign weights of 0.8 to class A and 0.2 to class B, the probabilities of being sampled for class A and B are 80% and 20%, respectively.
- Weight sampling can leverage domain expertise, which is important for reducing sampling biases. For example, in training some online learning models, recent data is much more important than old data. Through assigning bigger weights to recent data and smaller weights to old data, you can train a model more reliably.
- Reservoir Sampling - Reservoir sampling is an interesting and elegant algorithm to deal with streaming data in online learning models, which is quite popular in products. Suppose the data is generated in a sequential streaming manner, for example, a time series, and you can’t fit all the data to the memory, nor do you know how much data will be generated in the future. You need to sample a subset with k samples to train a model, but you don’t know which sample to select because many samples haven’t been generated yet.
- Reservoir sampling can deal with this problem that
- All the samples are selected with equal probability and
- If you stop the algorithm at any time, the samples are always selected with correct probability.
- The algorithm contains 3 steps:
- Put the first k samples in a reservoir, which could be an array or a list
- When the nth sample is generated, randomly select a number m within the range of 1 to n. If the selected number m is within the range of 1 to k, replace the mth sample in the reservoir with the nth generated sample, otherwise do nothing.
- Repeat 2 until the stop of algorithm.
- We can easily prove that for each newly generated sample, the probability of being selected to the reservoir is k/n. We can also prove that for each sample that is already in the reservoir, the probability of not being replaced is also k/n. Thus when the algorithm stops, all the samples in the reservoir are selected with correct probability.
- Cluster sampling - Here, we use the subgroups of the population as the sampling unit rather than individuals. The population is divided into subgroups, known as clusters, and a whole cluster is randomly selected to be included in the study. This type of sampling is used when we focus on a specific region or area. There are different types of cluster sampling — single stage, two stage and multi stage cluster sampling methods.
- Systematic sampling - Systematic sampling is a statistical method that researchers use to zero down on the desired population they want to research. Researchers calculate the sampling interval by dividing the entire population size by the desired sample size. Systematic sampling is an extended implementation of probability sampling in which each member of the group is selected at regular periods to form a sample.
- Systematic random sampling
- Linear systematic sampling
- Circular systematic sampling
Sampling errors
The two main types of errors that occur when performing data sampling are:
- Selection bias - The bias that’s introduced by the selection of individuals to be part of the sample that isn’t random. Therefore, the sample cannot be representative of the population that is looking to be analyzed.
- Sampling error - The statistical error that occurs when the researcher doesn’t select a sample that represents the entire population of data. When this happens, the results found in the sample don’t represent the results that would have been obtained from the entire population.
Sampling with replacement
Consider a population of potato sacks, each of which has either 12, 13, 14, 15, 16, 17, or 18 potatoes, and all the values are equally likely. Suppose that, in this population, there is exactly one sack with each number. So the whole population has seven sacks. If I sample two with replacement, then I first pick one (say 14). I had a 1/7 probability of choosing that one. Then I replace it. Then I pick another. Every one of them still has 1/7 probability of being chosen. And there are exactly 49 different possibilities here (assuming we distinguish between the first and second.) They are: (12,12), (12,13), (12, 14), (12,15), (12,16), (12,17), (12,18), (13,12), (13,13), (13,14), etc.
Datasets that are created with sampling with replacement so that they have the same number of samples as the original dataset are called bootstrapped datasets. Bootstrapped data is used in machine learning algorithms like bagged trees and random forests as well as in statistical methods like bootstrapped confidence intervals and more.

Sampling without replacement
Consider the same population of potato sacks, each of which has either 12, 13, 14, 15, 16, 17, or 18 potatoes, and all the values are equally likely. Suppose that, in this population, there is exactly one sack with each number. So the whole population has seven sacks. If I sample two without replacement, then I first pick one (say 14). I had a 1/7 probability of choosing that one. Then I pick another. At this point, there are only six possibilities: 12, 13, 15, 16, 17, and 18. So there are only 42 different possibilities here (again assuming that we distinguish between the first and the second.) They are: (12,13), (12,14), (12,15), (12,16), (12,17), (12,18), (13,12), (13,14), (13,15), etc.
Difference between sampling with replacement and sampling without replacement
- When we sample with replacement, the two sample values are independent. Practically, this means that what we get on the first one doesn't affect what we get on the second. Mathematically, this means that the covariance between the two is zero.
- In sampling without replacement, the two sample values aren't independent. Practically, this means that what we got on the for the first one affects what we can get for the second one. Mathematically, this means that the covariance between the two isn't zero. That complicates the computations.
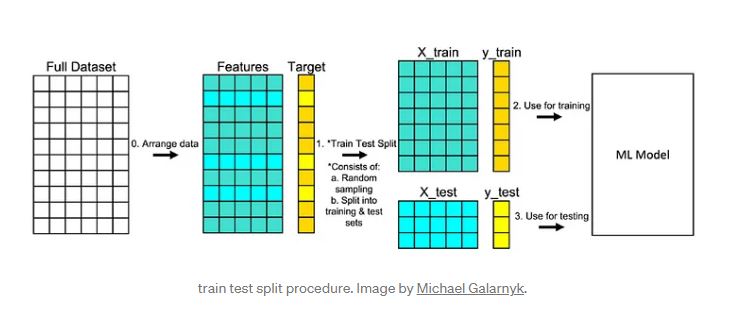
Sampling without replacement is used throughout data science. One very common use is in model validation procedures like train test split and cross validation. In short, each of these procedures allows you to simulate how a machine learning model would perform on new/unseen data.
Sources
- Simply Psychology
- Suresha HP
- Analytics Vidhya
- Shuchen Du
- Michael Galarnyk




