When training a machine learning model, one ought to split the dataset as a pre-requisite to training. This article explains in detail the train_test_split sklearn's function that is used for this purpose.
Using scikit-learn's library you can use train_test_split() to split your dataset into subsets that minimize the potential for bias in your evaluation and validation process.
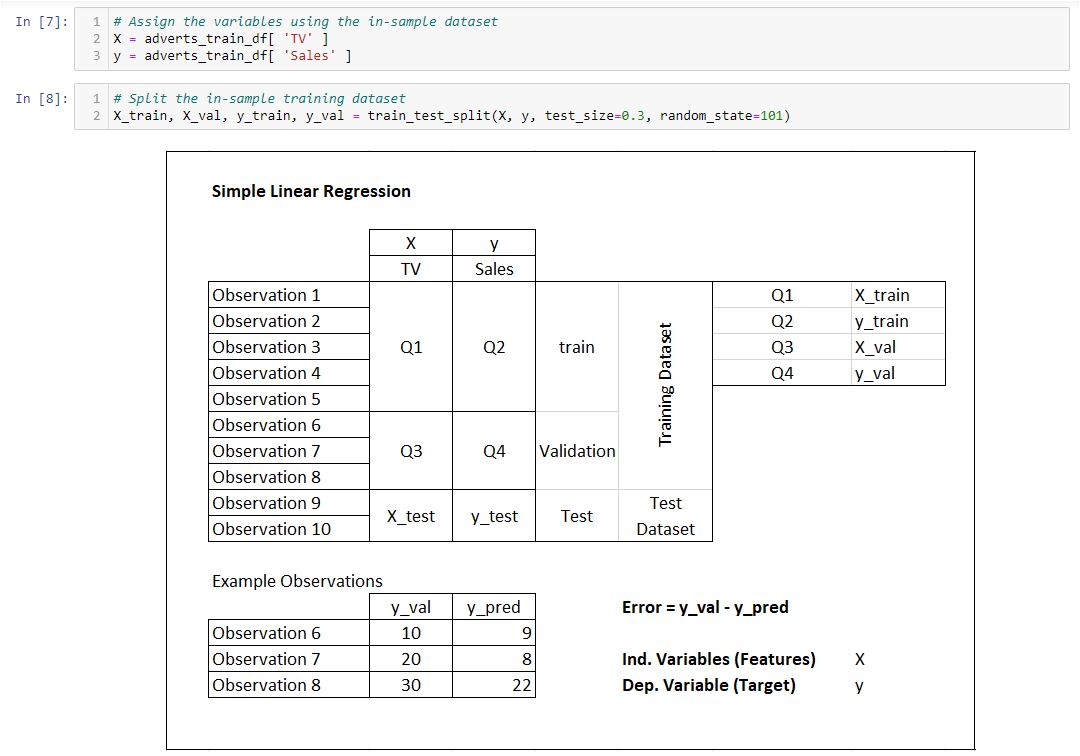
Training, Validation and Test Datasets
Training dataset - applied to train, or fit the model. For example, you use the training set to find the optimal weights, or coefficients, for linear regression, logistic regression or neural networks.
Validation dataset - used for the unbiased model evaluation during hyperparameter tuning. For example, when you want to find the optimal number of neurons in a neural network or the best kernel for a support vector machine, you experiment with different values. For each considered setting of hyperparameters, you fit the model with the training set and assess its performance with the validation set.
Test dataset - needed for the unbiased evaluation of the final model. This should not be used for fitting or validation
Underfitting and Overfitting
Underfitting - usually the consequence of a model being unable to encapsulate the relations among data. For example, this can happen when trying to represent nonlinear relations with a linear model. Underfitted models will likely have poor performance with both training and test sets.
Overfitting - usually takes place when a model has an excessively complex structure and learns both the existing relations among data and noise. Such models often have bad generalization capabilities. Although they work well with training data, they usually yield poor performance with unseen (test) data.
The train_test_split() function
The parameters are as below:
train_size - this defines the size of the training dataset, default is None.
test_size - this is the number that defines the size of testing dataset, default is 0.25
random_state - this is the object that controls randomization during the splitting, default is None
shuffle - determines whether to shuffle the dataset before applying the split, default is True
stratify - determines how to use a stratify split. Stratified splits are desirable in some cases, like when you’re classifying an imbalanced dataset, a dataset with a significant difference in the number of samples that belong to distinct classes.