

How exactly is big data extracted from the various sources, transformed into formats and shapes that can be easily consumed by data analysts, data scientists and machine learning engineers? This is the main work of Amazon Glue which simplifies the seamless transformation.
What is Amazon Glue
Amazon Glue is a server less ETL that extracts data from source, transforms it in the right way to be consumed and finally loads it back to storage for access. It is a server less data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML) and application development. AWS Glue is a serverless data integration service that makes data preparation simpler, faster, and cheaper. You can discover and connect to over 70 diverse data sources, manage your data in a centralized data catalog, and visually create, run, and monitor ETL pipelines to load data into your data lakes.
Components of AWS Glue
Event Driven
AWS Glue can run your extract, transform and load (ETL) jobs as new data arrives. For example, you can configure AWS Glue to initiate your ETL jobs to run as soon as new data becomes available in Amazon Simple Storage Service (S3).
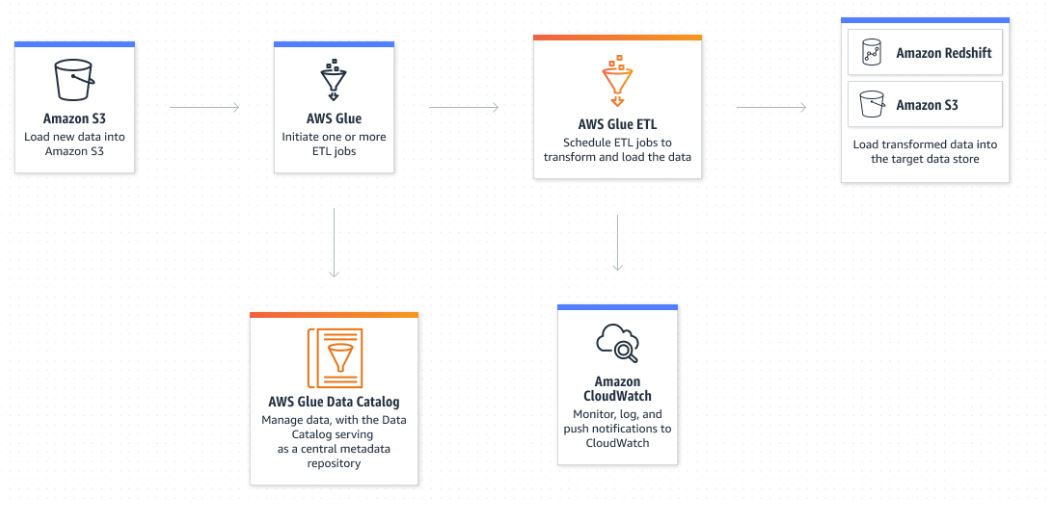
Amazon Glue Data Catalog
You can use the Data Catalog to quickly discover and search multiple AWS datasets without moving the data. Once the data is cataloged, it is immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
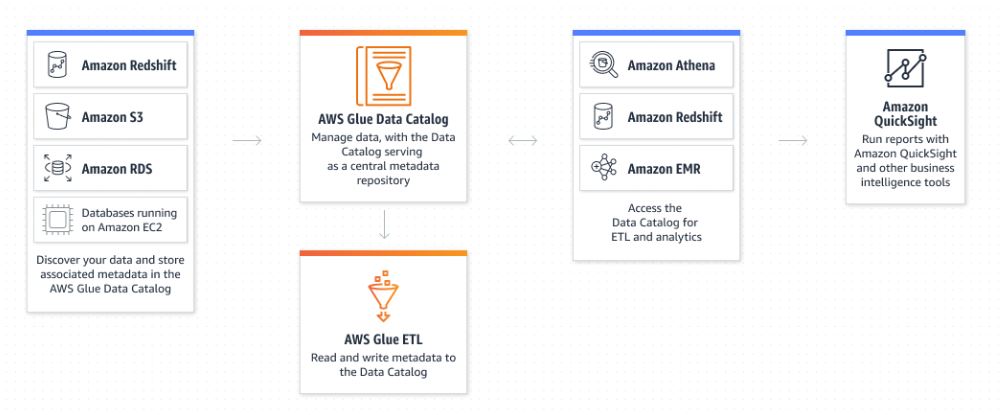
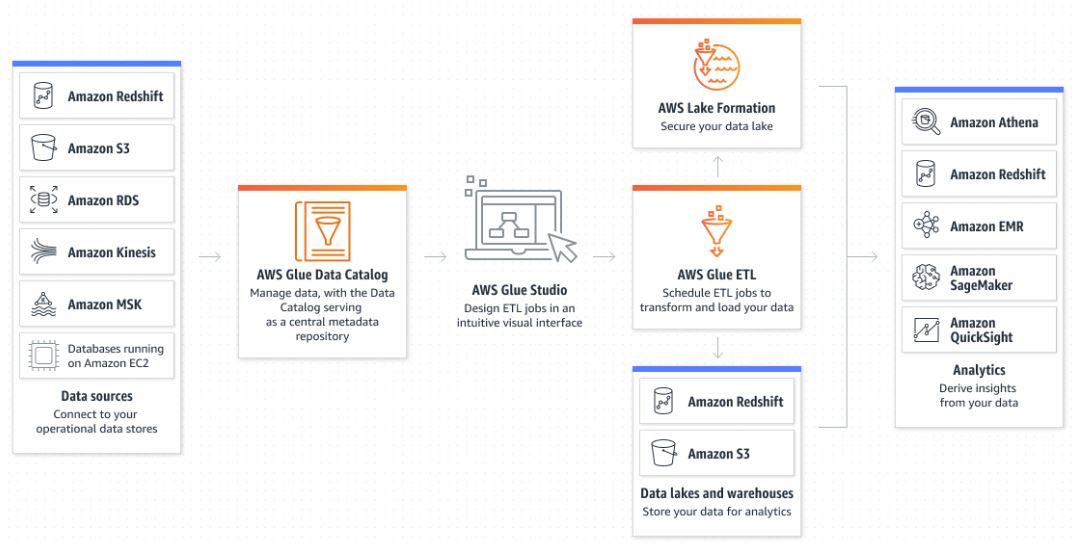
No-Code ETL Jobs
AWS Glue Studio makes it easier to visually create, run, and monitor AWS Glue ETL jobs. You can build ETL jobs that move and transform data using a drag-and-drop editor, and AWS Glue automatically generates the code.
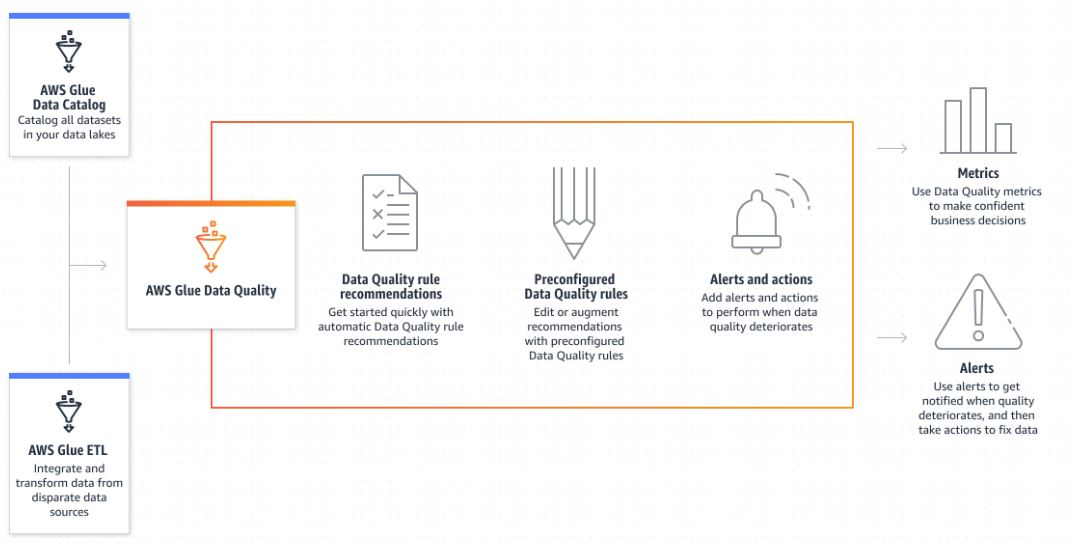
Manage and Monitor Data Quality
AWS Glue Data Quality automates data quality rule creation, management, and monitoring to help ensure high quality data across your data lakes and pipelines.
Data Preparation
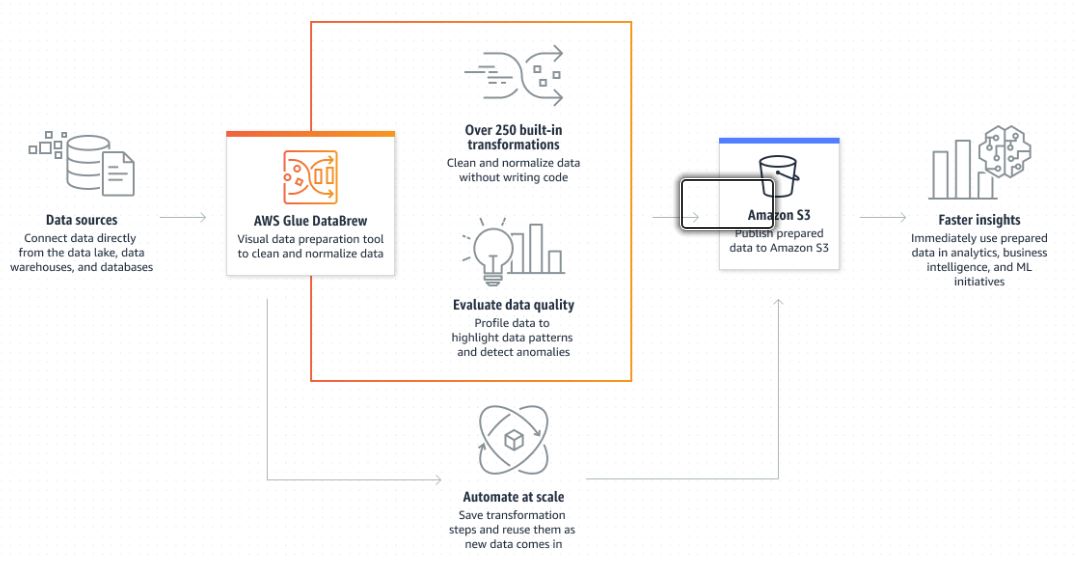
With AWS Glue DataBrew, you can explore and experiment with data directly from your data lake, data warehouses, and databases, including Amazon S3, Amazon Redshift, AWS Lake Formation, Amazon Aurora, and Amazon Relational Database Service (RDS). You can choose from over 250 prebuilt transformations in DataBrew to automate data preparation tasks such as filtering anomalies, standardizing formats, and correcting invalid values.
Advantages of using Amazon Glue
Practical Implementations
Sources


