
")
Bias and Variance are prediction errors when it comes to accuracy in any machine learning algorithm. Bias refers to how well your model can represent all possible outcomes, whereas variance refers to how sensitive your predictions are to changes in the model’s parameters.
Bias and variance are two important properties of machine learning models.
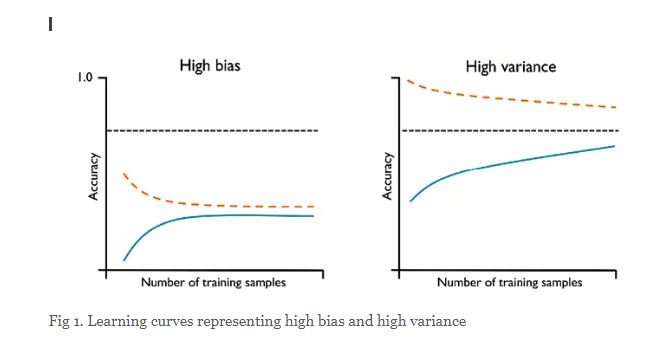
High Bias Models (Underfitting): The plot on the left side represents the model having both low training and validation accuracy. This indicates that that the model under fits the training data and thus, is the case of high bias. You may notice that as the training samples size increases, the training accuracy decreases and validation accuracy increases. However, the validation accuracy is far from the desired accuracy.
One way to tackle the high bias of machine learning models is to add more features to the training data. This will allow the model to learn more complex relationships and hopefully reduce the bias. Adding more features to a machine learning model can help reduce the model bias. This is because more features give the model more data to learn from, which can help it to become more accurate.
Another way to tackle high bias is to use a different machine learning algorithm that is better suited for the data. Finally, it is also possible to combine multiple models to create a more accurate prediction.
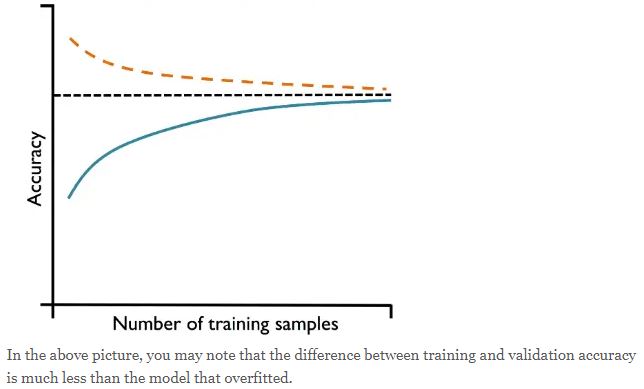
The plot on the right side represents a model that has large gap between training and validation accuracy. The training accuracy is larger than the validation accuracy. These models suffer from high variance (overfitting). You may notice that as the training samples size increases, the training accuracy decreases and validation accuracy increases. However, the training accuracy is much greater than validation accuracy and also desired accuracy.
Some of the ways to address this problem of overfitting are following:
Bias-Variance Tradeoff
If the algorithm is too simple (hypothesis with linear eq.) then it may be on high bias and low variance condition and thus is error-prone. If algorithms fit too complex ( hypothesis with high degree eq.) then it may be on high variance and low bias. In the latter condition, the new entries will not perform well. Well, there is something between both of these conditions, known as Trade-off or Bias Variance Trade-off.
Sources


