

It is quite tasking to build a data lake. However, after achieving the hurdle, how best do you utilize it to the advantage of the enterprise. One of the main efficient use of a data lake would be to drive analytics and machine learning tasks on top of it. The efficient way of implementing this is by setting up a machine learning pipeline and this article talks about building Machine Learning pipelines using Amazon SageMaker.
What
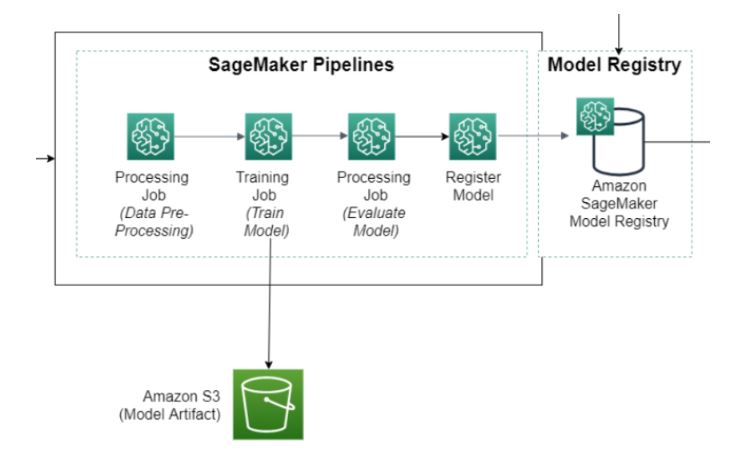
With Amazon SageMaker Pipelines, you can create, automate, and manage end-to-end machine learning (ML) workflows at scale. You can use Amazon SageMaker Model Building Pipelines to create end-to-end workflows that manage and deploy SageMaker jobs. SageMaker Pipelines comes with SageMaker Python SDK integration, so you can build each step of your pipeline using a Python-based interface.
After your pipeline is deployed, you can view the directed acyclic graph (DAG) for your pipeline and manage your executions using Amazon SageMaker Studio. Using SageMaker Studio, you can get information about your current and historical pipelines, compare executions, see the DAG for your executions, get metadata information, and more.
The pipeline that you create follows a typical machine learning (ML) application pattern of preprocessing, training, evaluation, model creation, batch transformation, and model registration
SageMaker Projects
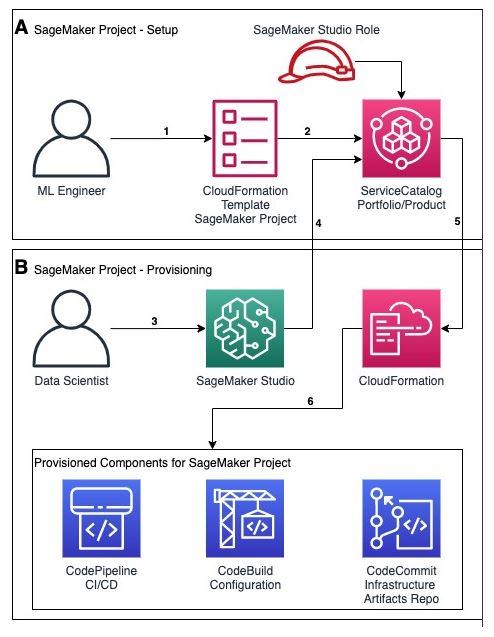
SageMaker projects build on SageMaker Pipelines by providing several MLOps templates that automate model building and deployment pipelines using continuous integration and continuous delivery (CI/CD). SageMaker Projects help organizations set up and standardize developer environments for data scientists and CI/CD systems for MLOps engineers. Projects also help organizations set up dependency management, code repository management, build reproducibility, and artifact sharing.
With SageMaker Projects, MLOps engineers and organization admins can define their own templates or use SageMaker-provided templates. The SageMaker-provided templates bootstrap the ML workflow with source version control, automated ML pipelines, and a set of code to quickly start iterating over ML use cases.
Step Types
SageMaker Pipelines provides many predefined step types, such as:
Activities in SageMaker Pipelines
SageMaker pipelines supports the following activities
Benefits of a Machine Learning Pipeline
MLOps is a machine learning engineering culture and methodology that helps to bring together the creation and application of machine learning systems (Ops). Using MLOps pipelines means advocating for automation and tracking in the ML system development process, including integration, checking, launching, rollout, and infrastructure management. Some advantages are:
Practical Implementations
Sources


